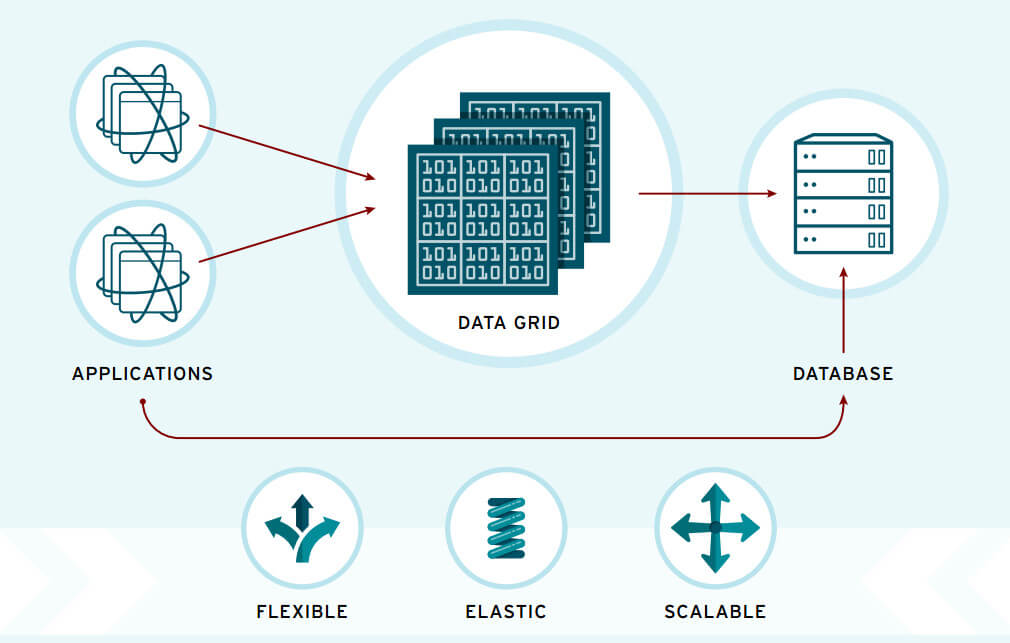
A Red Hat Data Grid egy NoSQL adatbázis és adat-cache, adatok extrém gyors memória alapú tárolására és elérésére

Magas rendelkezésre állású adathozzáférés
Ahogy az adatok mennyisége növekszik, a hagyományos back-end adattárak írása és olvasása jelentős teljesítményproblémákat okozhat a webes alkalmazások esetén. Azáltal, hogy a helyes, releváns adatokat memóriába helyezi és biztosítja az adatközpontok közötti magas rendelkezésre állást, a Red Hat Data Grid egy kiegészítő réteget hoz létre az alkalmazások és a hagyományos relációs adatbázisok között. Ez a réteg biztosítja az alkalmazások számára, hogy teljesíthessék az adatmegőrzéssel kapcsolatos követelményeket, extrém sebességű és skálázható írási-olvasási teljesítményt elérve és betartva a rendelkezésre állással kapcsolat SLA követelményeket.
Rugalmas skálázódás a gyors válaszidő eléréséhez
Számos alkalmazás számára jelent komoly problémát, hogy az írási és vagy olvasási terhelések „kampányszerűen” jelentkeznek, például szezonális jellegű kereskedelmi tevékenységeket kiszolgáló alkalmazásoknál (pl. akciók), különböző marketing és promóciós események során, vagy ahol az alkalmazás működését külső események befolyásolják. Ezen alkalmazások működése szempontjából kritikus, hogy költséghatékony, ugyanakkor „hatásmentes” (non-disruptive) módon lehessen azokat rugalmasan skálázni, minden esetben biztosítva a működéssel szemben elvárt válaszidőket. A Data Grid leegyszerűsíti új node-ok hozzáadását vagy meglévőek eltávolítását (a klaszterből), ráadásul a háttérben automatikusan biztosítja, hogy minden adat elosztva, replikálva továbbra is folyamatosan rendelkezésre álljon.