Hogyan védekezzünk a nagy kihasználtságú erőforrások meghibásodása ellen? A hardverköltségeket úgy csökkenthetjük, hogy a sok kis szervert kisszámú blade szerverrel, valamint a fizikai szervereket virtuális gépekkel helyettesítjük. De mi lesz a virtuális gépek rendelkezésreállásával? Hogy tudjuk kihasználni a virtualizáció kínálta előnyöket?
A probléma: hogyan védekezzünk a nagy kihasználtságú erőforrások meghibásodása ellen?
Régóta dolgozunk az IT költségek lecsökkentésén. Ennek érdekében sort kerítünk például a rendszeradminisztráció folyamatának automatizálására, és így a rendszeradminisztrációs munkatársakkal kapcsolatos költségek csökkentésére. A hardverköltségeket pedig úgy csökkenthetjük, hogy a sok kis szervert kisszámú blade szerverrel, valamint a fizikai szervereket virtuális gépekkel helyettesítjük.
A virtualizáció nagy lehetőségeket rejt magában. Egyre több szoftvert futtatunk – beleértve küldetéskritikus alkalmazásokat is – virtuális gépeken. Ezzel minden rendben van; a költségek egyre csökkennek. Azonban mi történik akkor, ha valaki véletlenül megbotlik egy tápkábelben, amivel egy fizikai szervert leállít és ezáltal minden virtuális gépet, amit az hosztolt. Viszont a probléma már nem virtuális, hiszen a virtuális gépek közül néhány ügyféloldali alkalmazásokat támogatott, míg a többi a vállalat raktárkezelő-rendszerét futtatta. Amire itt szükségünk van, az a failover funkcionalitás minden virtuális vendégrendszer számára. Már régóta tudunk a fizikai szerverek klaszterezésének failover lehetőségeiről, de amikor elkezdünk virtuális gépeket hozzáadni, senki sem gondol a failoverre. Ez eddig nem is volt lehetséges, de a RHEL Advanced Platform megnyitja ezt a lehetőséget.
A megoldás – klaszter failover
Nézzük meg, hogy hogyan nyújt failover védelmet a virtuálisgép-környezet számára a Red Hat Enterprise Linux Advanced Platform használata! Az alábbi ábra három gépet mutat, mindegyiken két Enterprise Linux vendégrendszerrel. A baloldai képen azt látjuk, hogy a szerver fizikailag meghibásodik. Normális esetben az A és B vendégrendszerek addig nem működnének, amíg egy rendszeradminisztrátor meg nem oldja a problémát. Azonban, mivel a gépek menedzselésére az Advanced Platform lett konfigurálva, a fizikai gép meghibásodását a klaszter automatikusan felismeri, és a vendég A és B rendszerek a másik két szerveren automatikusan újraindulnak.
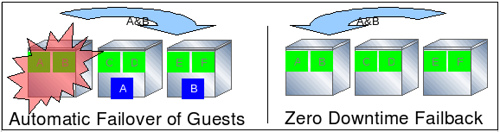
Amint az adminisztrátor megoldja a problémát a baloldai géppel, a két vendégrendszer futás közben visszamigrálható a most már működő rendszerre. Ez egy példa a nulla üzemidő-kiesésre, visszakapcsolás esetén. A virtuális vendégrendszerek nemcsak gyorsan és automatikusan újraindulnak, hanem nem az alkalmazás futása is zavartalan a konfiguráció újbóli kiegyensúlyozása során.
A részletek
Hogyan valósul ez meg? Az alábbi ábra egy megvalósítási példát mutat be. A gépek beállításában a kulcsfontosságú változás az az, hogy a három fizikai gépet megosztott erőforrásként kezeljük. A megvalósításban iSCSI SAN eszközöket is használhatunk, melyek szabványos Ethernet adaptereket, switcheket és csatlakozókat használnak.
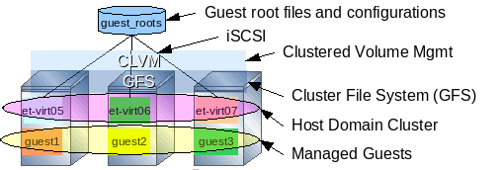
A storage-kezelésen, a Xen virtualizáción és a klaszterkezelésen túlmenően felhasználjuk még a GFS2-t, az Advanced Platform klaszter fájlrendszerét azért, hogy blokkszintű, magas teljesítményű működést nyújtson a gépek közötti kommunikációban. A konfiguráció és a vendégrendszerek rendszertöltési képmásai (boot image) egy közös GFS2 fájlrendszerben tárolódnak. Ez lehetővé teszi a vendégrendszerek indítását bármelyik gépen, valamint a futás közbeni migráció végrehajtását.
Felkeltettük az érdeklődését? Szeretne többet is megtudni a részletekről? Lépjen velünk kapcsolatba e-mailen vagy telefonon.